
Can Kafka Queues Make Consumers Faster?
Not so fast!

For a while, messaging systems like RabbitMQ, ActiveMQ, and AWS SQS have been used as a foundational component of many enterprise architectures. Enterprise Integration Patterns is still one of my favourite books. I had my first exposure to messaging systems many years ago: I worked at a startup where we used a combination of ActiveMQ, Camel, and Akka to build event-driven microservices.
Then Apache Kafka became popular. The Distributed Log is a more generic abstraction, but many people have tried using it as a message queue, not always successfully.
Finally, Apache Kafka 4.x introduced Queues as a first-class citizen! And Queues are officially GA in Kafka 4.2.0.
Many more knowledgeable engineers have already extensively written about this:
And the official KIP-932: Queues for Kafka.
Instead of repeating after everyone, I wanted to explore one idea that immediately came to mind once I learned about the Queues.
What’s in It for Data Streaming Engineers?
Queues are a great building block if you’re building a workflow orchestrator, a task scheduler, event-driven microservices, etc.
But what about data streaming projects? Will Queues help with Spark, Flink, Kafka Connect, and similar technologies?
I thought they could be applicable in two ways:
Helping to build complex state machines. For example, if your stream-processing engine needs to perform a lot of work per message (e.g., calling an external endpoint, enriching data, performing conditional lookups), the ability to acknowledge or reject and reprocess messages is really valuable. Ideally, you also want to use the Dead Letter Queue (DLQ): it’s coming to Kafka as a first-class citizen too.
Scaling consumers beyond the partition count. The parallelism of Kafka consumers is generally limited by the partition count: you can’t have more instances consuming data than the number of partitions. There are some workarounds (like multi-threading consumers), but they’re quite complex and not supported in popular OSS projects like Spark and Flink. Queues seemed to offer a solution: a share group (a new Queues feature) can have more instances than partitions, and the work will be distributed accordingly.
I focus on the latter next. It seems great in theory, but does it actually work? I decided to test it.
The Benchmark
3-node Apache Kafka 4.2.0 cluster deployed using Strimzi Operator 0.51.0 on m8i.xlarge machines in AWS.
A single topic with 4 partitions and 400M records, each record is a JSON payload with 1KB average size.
Two Kafka consumer apps that read data from the topic (using the Bytes deserializer, so no JSON deserialization overhead) as fast as possible, perform some conditional logging, but nothing else (essentially no-op).
The Standard Consumer app just uses the regular KafkaConsumer
The Share Consumer app uses the new KafkaShareConsumer with implicit acknowledgement and batch_optimized share.acquire.mode.
Both consumers have the standard high-throughput tuning (increased fetch.max.bytes, fetch.max.wait.ms, max.partition.fetch.bytes, etc.)
Kafka brokers were configured with:
group.coordinator.rebalance.protocols: “classic,consumer,share”
share.coordinator.state.topic.replication.factor: 3
share.coordinator.state.topic.min.isr: 2
group.share.partition.max.record.locks: 10000
group.share.record.lock.duration.ms: 15000
group.share.delivery.count.limit: 10As I understand, group.share.partition.max.record.locks is especially important for high throughput - we’d like to process as many records as possible. 10000 is the maximum value allowed.
I ran several experiments:
Standard consumer (baseline): 1 instance and 4 instances. Can’t go higher because of the partition limit.
Share consumer: 1 instance, 4 instances, 8 instances. The goal was to compare with the baseline and observe the throughput increase with more instances.
The logic of the share consumer looked like this (a bit simplified):
AtomicBoolean running = new AtomicBoolean(true);
try (KafkaShareConsumer<byte[], byte[]> consumer = new KafkaShareConsumer<>(props)) {
consumer.subscribe(List.of(topic));
long consumed = 0L;
while (running.get()) {
ConsumerRecords<byte[], byte[]> records = consumer.poll(pollTimeout);
consumed += records.count();
// logging the number of consumed messages and the processing rate
// every 5 seconds
}
}Results
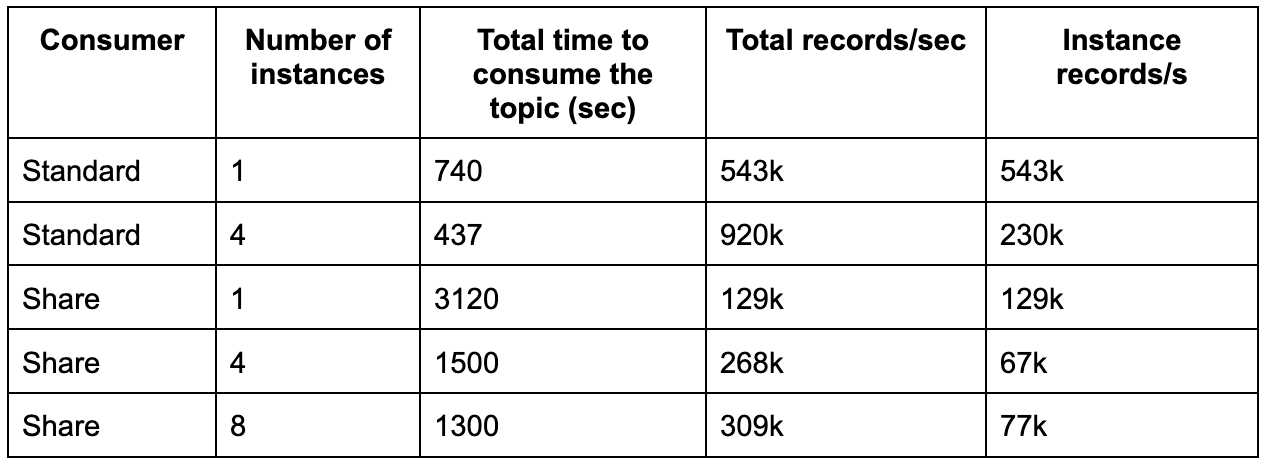
As you can see, the standard consumer was able to achieve almost 1M rec/s throughput with 4 instances.
The throughput of the new share consumer is dramatically lower. We can definitely see the improvement when adding more instances, but the difference is still brutal: even eight instances of the share consumer are slower than a single standard one.
Analysis and Conclusion
So, why is the share consumer performance so different? I’m not a KIP-932 expert; I might be missing something (in which case, I welcome feedback!). But, as far as I understand:
Queues add additional overhead. They’re designed around the idea of acquisition locks, and the locks are managed on the broker side.
Most importantly, even though you can have multiple instances receiving the data on the consumer side, the fetching is still pretty much bottlenecked by the number of partitions:

Perhaps throughput could be improved if the fetch-from-follower optimization is implemented by the share groups, but it seems quite challenging (the state will have to be distributed).

Apache Kafka Queues is a very powerful abstraction, but as far as I can see, it won’t simply eliminate partitions as a scaling bottleneck for your consumers. At least, not yet.
Other Posts
I recently wrote Postgres to Iceberg in 13 minutes: How Supermetal compares to Flink, Kafka Connect, and Spark and Apache Flink: Reading and Modifying Kafka Consumer Offsets Using the State Processor API, which you may find interesting.
Advanced Apache Flink
Advanced Apache Flink is an on-demand course focused on Flink internals, production deployment best practices, and advanced patterns.
The use case that comes to mind is when the processing time per message is large. Then you'd want to scale-up consumers as the length of the queue grows. Run the benchmark again with a long constant delay in each consumer.