
Current New Orleans 2025
Conference highlights.

Current 2025 happened last week in New Orleans, USA. I’ve had a chance to attend it, and I’d love to share some of my notes with you.
Keynotes & Announcements
Confluent Intelligence likely was the biggest announcement. It’s a combination of three products:
Built-in ML functions for forecasting, anomaly detection, fraud detection, etc. These are implemented as Flink UDFs that call internal models. Some examples: ML_FORECAST, ML_DETECT_ANOMALIES, ML_PREDICT, etc. I believe that at least some of these functions have been supported for a while.
Streaming Agents. I’m not a big fan of this name. There is actually very little agentic functionality: if you think about it, these are Flink pipelines with UDFs that can call LLMs and MCP servers. That’s it. In my opinion, a truly agentic framework needs to support branching, loops, and, most importantly, somewhat non-deterministic execution that’s generated by the LLM output. So, workflow orchestration frameworks such as Restate, Temporal, DBOS, etc., are a better fit for this, in my opinion.
Real-Time Context Engine. A fancy name for what it seems like, an in-memory query engine (likely an Incremental View Maintenance system), which sits on top of hot (Kafka) and cold (Iceberg) data and exposes itself over MCP. This is the most interesting announcement for me, because the IVM system will actually be useful even after the current AI bubble bursts. Building a new IVM system is no small feat, and I’d love to learn more about its implementation!
And I have to mention Airy’s acquisition (acquihire?). Airy had a lot of experience with Flink AND LLMs, so this move makes a lot of sense.
Confluent Private Cloud is another big announcement worth mentioning. Confluent is going to offer a flavour of its cloud product for on-prem deployments. But I’m confused: they already have Confluent Platform for that (which still generates a lot of revenue), so will Private Cloud replace Platform? Complement it? Evolve it? Someone, please clarify. You could also say that WarpStream is another on-prem product offered by Confluent, so will they compete?
By the way, WarpStream was mentioned for about 10 seconds in a 2-hour keynote. I understand they still operate as a separate org, but they build a lot of cool features. Please share them with the world!
Another series of announcements was about Tableflow. Support for Delta Lake and Unity Catalog is now GA. They also released upserts and DLQs (Dead Letter Queues). It’s funny to see how much Confluent invests in better supporting Databricks as a partner, while Databricks is working on a data ingestion solution that doesn’t require Kafka…
Most of the other announcements can be found here.
Other random observations:
Jay Kreps (CEO @ Confluent) noticed the importance of Flink batch jobs for iterating on data.
Shawn Clowes (CPO @ Confluent), about Flink: “One of the most successful products we’ve ever launched as a company”.
Also from Shawn: we have “the largest number of connectors in the entire streaming ecosystem”. Seems like it’s targeting Redpanda Connect (which claims a higher number of connectors).
AI
Stateful computations such as aggregations, joins and windowing, as well as products like Streaming Agents and Real-Time Context Engine, enable Flink to do one thing really well: build context for LLMs. I don’t think it’s currently capable of much more than that, but building real-time, highly personalized and relevant context is already a big win. As I mentioned above, I don’t believe we should be calling it an agentic framework, but does it really matter?
“Just” being the best way to build LLM context should make data streaming extremely attractive in the current AI hype cycle.
Confluent announced Real-Time Context Engine last week, but some companies have been working on similar approaches for a while. For example, check the DeltaStream blog, which shares many concrete use cases for building context using Flink stateful operations and then calling LLMs.
Of course, aside from the announcements, AI was a hot topic in many private conversations I had. In person, most people are not very impressed with the current AI tooling (just as I am), to say the least. Stanislav Kozlovski nicely summarized my concerns, and he didn’t even touch on the moral or environmental considerations. And, sometimes, I feel like Emma Thompson.
I can’t say what’s going to happen, but I feel like we’re in some sort of bubble. If you overly rely on AI tools right now, my suggestion is to have a backup plan (for when the underlying service either completely disappears or increases its price by 10x - 100x).
Interesting Talks
Here are some of the interesting talks I’ve had a chance to attend.
FlinkSketch: Democratizing the Benefits of Sketches for the Flink Community
This was a short, lightning talk about FlinkSketch: a library of sketching algorithms for Flink. I think this library deserves more attention: it’s very common to use Flink for streaming analytics and generating ML features, both of which typically rely on windowed aggregations.
Sketching algorithms can significantly reduce resource usage (e.g., memory) while slightly sacrificing accuracy. This is a great compromise for many workloads.
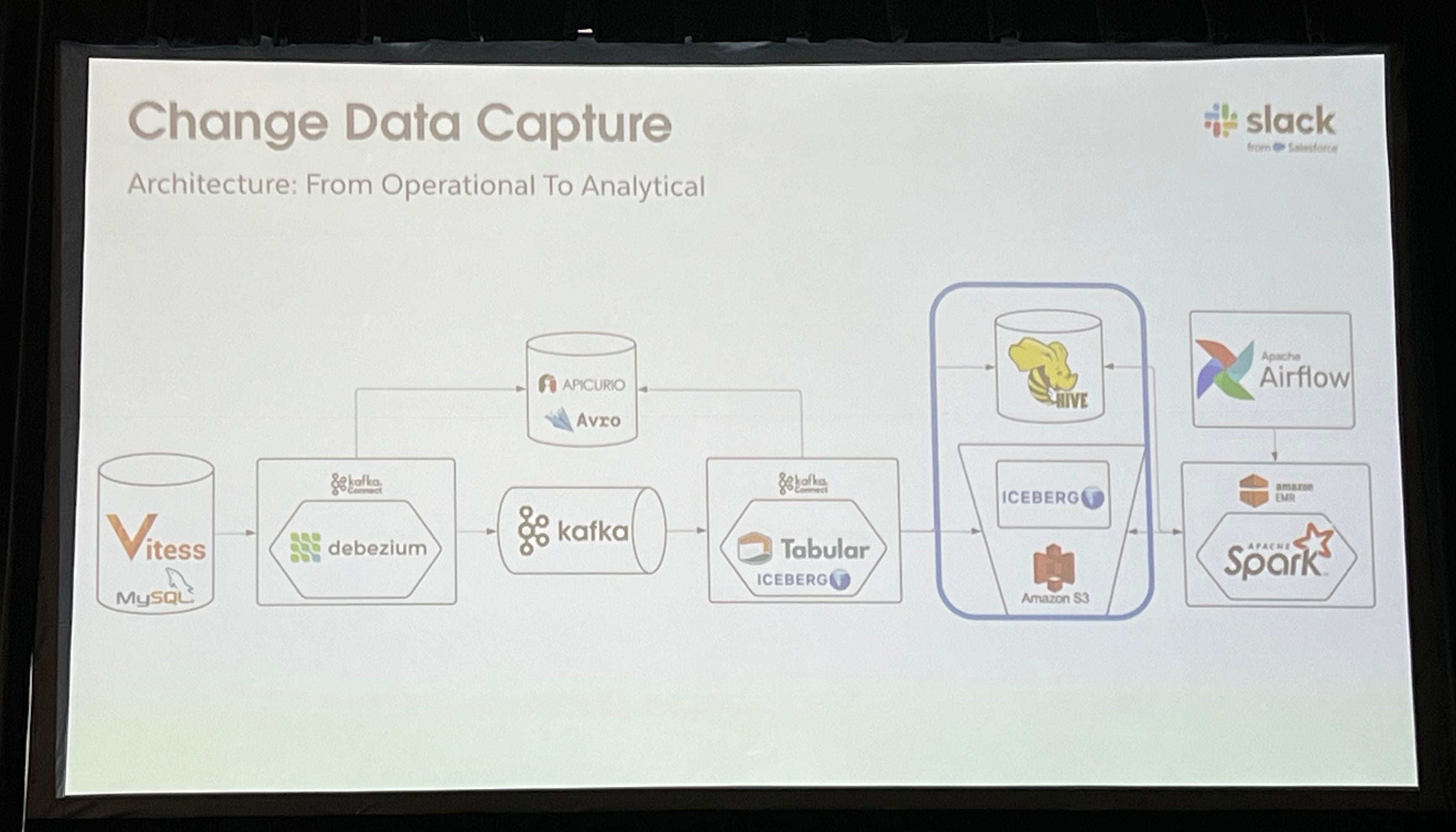
Change Data Capture at Scale: Insights from Slack’s Streaming Pipeline
This was a talk about the Change Data Capture architecture for Slack’s sharded MySQL setup (Vitess). I really liked the very methodical approach to performance optimizations; it can be generally applied to most data-intensive applications.
Making agents, workflows, and event-driven apps as simple as SpringBoot, with Restate
The latest demo of Restate, a durable execution engine. Even if you’re somewhat familiar with the product, it might still be worth watching: I was surprised to discover it now comes with a very powerful UI for introspecting any aspect of execution.
I’m not sure if it was recorded at all, but if it was, watch the recording until the end. You may hear a Grammy-winning marching band crashing the talk (only in New Orleans!)
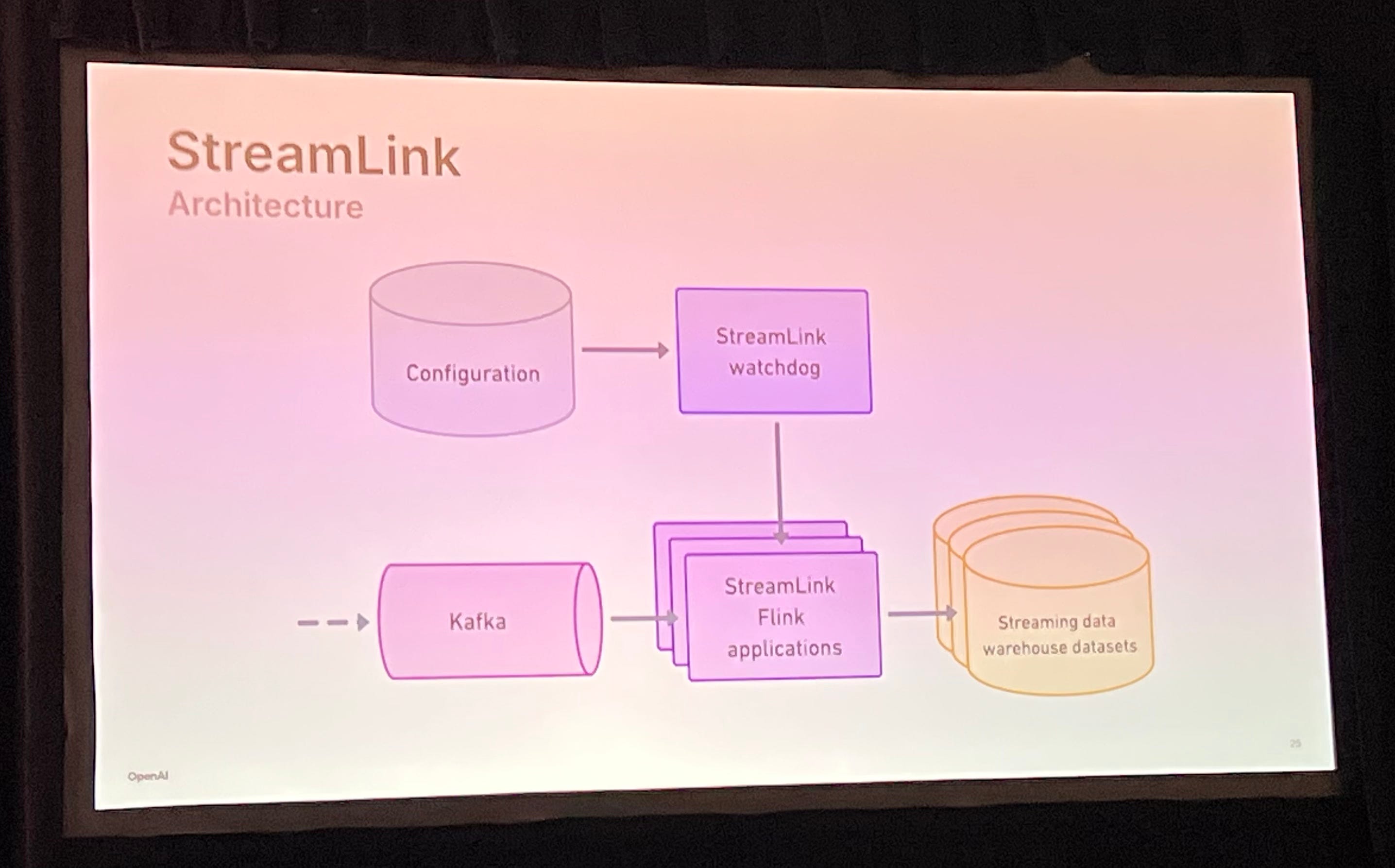
StreamLink: Real-Time Data Ingestion at OpenAI Scale
Insightful talk about OpenAI’s Flink infrastructure in the context of data ingestion. OpenAI uses YAML files for topic configuration (surprise) with the ability to add any topic for data lake ingestion. I also liked the clever use of Airflow sensors to mark partitions as completed.
In addition, they covered many details about their Flink control plane called Watchdog, which relies on the Flink Kubernetes Operator. Some great learnings here about the Flink Table API challenges and issues with job restarts.
Sizing, Benchmarking and Performance Tuning Apache Flink Clusters
Great talk from Robert Metzger, Flink PMC. A lot of it was about establishing a systematic approach to performance engineering, including setting a baseline, running experiments, and employing first-principles thinking. He also talked about choosing between horizontal and vertical scaling, tuning RocksDB and Kafka producers, as well as tweaking Flink memory.
If you are interested in improving the performance of your Flink pipelines, you may want to scroll to the end of the newsletter 😉.
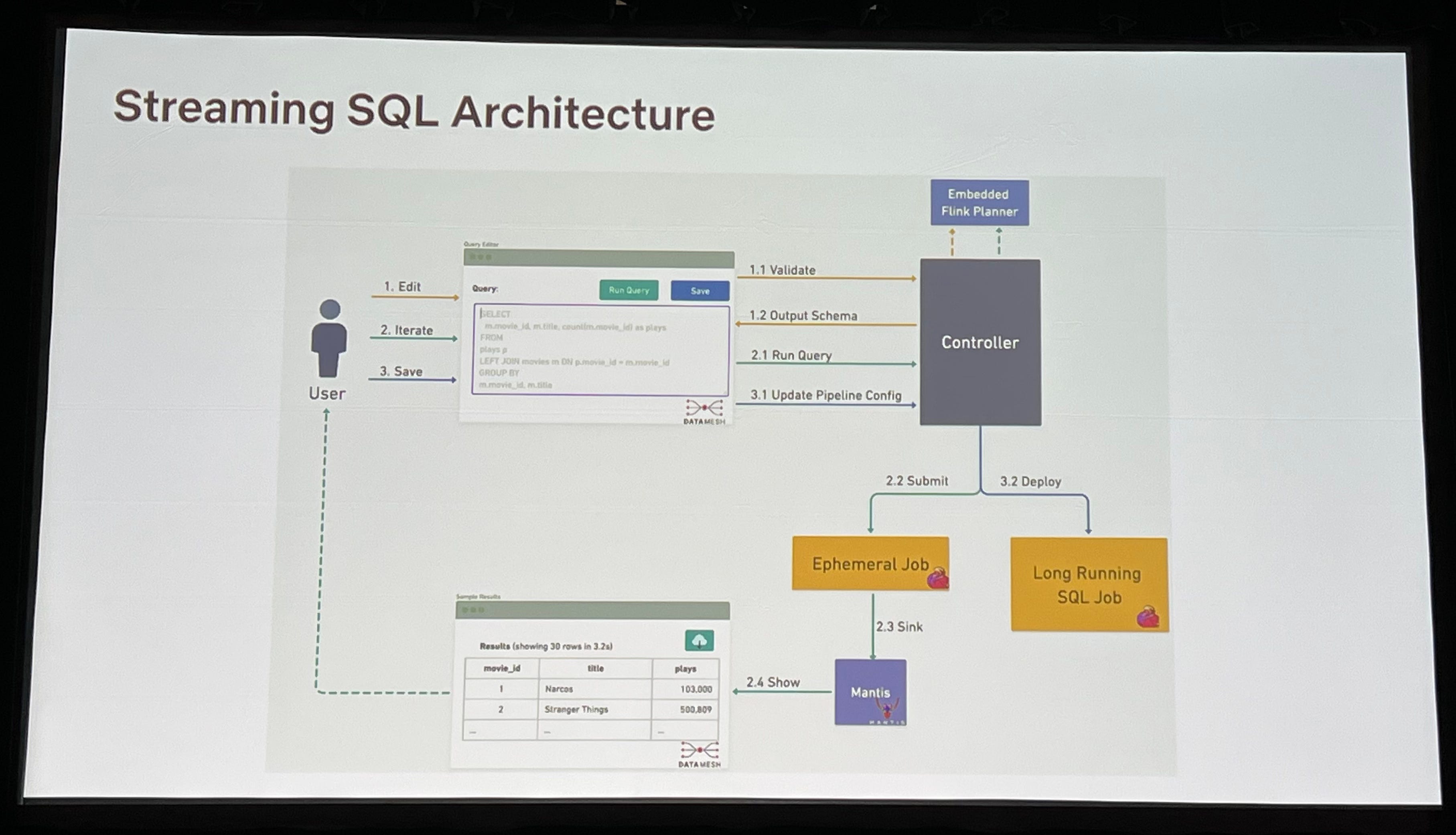
Press Play on Data: Netflix’s Journey from Streams to Gaming Insights
Great talk about Netflix’s Streaming SQL (Flink) infrastructure and a specific gaming insights use case. I like how many guardrails and validation checks it has, which are absolutely necessary when operating thousands of Flink pipelines.
Many gaming-related challenges reminded me of the challenges we faced back at Activision: even though the games could be very different, collecting, analyzing and storing telemetry data can be similar.
Redpanda Resistance
As you may recall, Redpanda was banned from Current London earlier this year. It looks like the ban is still in effect, but Redpanda is not giving up.
In addition to buying ads in the New Orleans airport (which happened to run after the Confluent ones), they also set up a camp directly across the street from the conference venue. They had puppies, ice cream and good vibes.
By the way, a day before Current, Redpanda announced a new Agentic Data Plane, as well as the Oxla acquisition, which will allow them to offer a SQL query engine on top of their data. I’m particularly excited about it because SQL is useful not just for agents!
You can learn more at Redpanda Streamfest later this week.
Confluent Catalysts
I’m thrilled to be in the Confluent Community Class of 2025 - 2026! I attribute this to the newsletter you’re reading, so thank you A LOT for that!
Upstream: New Webinar Series
I was fortunate enough to be the first guest on a new webinar series called Upstream by Jan Siekierski, you can watch the first episode here.
Data Streaming Academy
I’ve recently announced Data Streaming Academy: the best place to master data streaming technologies. Join the waitlist now to be notified about the upcoming Advanced Apache Flink bootcamp.