
Kafka Summit London 2024
Conference highlights.

Last week I was fortunate enough to attend the Kafka Summit conference in London. It’s organized by Confluent and showcases many data streaming technologies including Apache Kafka and Apache Flink.
Confluent Announcements
The keynote mostly repeated various announcements made at Current 2023 and in the last few months. Kafka will get a lot of new features. Kora is fast. More connectors. Lower price.
Flink GA
Confluent Cloud for Apache Flink becoming generally available was one of the big announcements.
And I think it looks quite good! The SQL Workspaces UI is nice, the integration with Kafka is top-notch, and Flink Actions is a great way to onboard new users.
Kudos for mentioning “scale to zero” during the keynote. It became one of the key characteristics of a truly serverless offering (Corey Quinn would be happy).
But it’s still early! The billing model is always a great indicator of a product's maturity. The current one is very simplistic. It doesn’t even account for state! Google Dataflow was like that several years ago and look at their pricing page now.
Tableflow
Of course, Tableflow was the main announcement (also see Jack Vanlightly’s post).
Confluent Cloud will expose Kafka’s tiered storage as Iceberg tables. They’ll be used as a sink (soon), source (in the future), and, most importantly, could be used in the Hybrid Source pattern to support historical reprocessing and backfills for Flink.
It’ll handle compaction, schema evolution, and integration with external query engines like Trino, Spark, Snowflake, etc. via an Iceberg catalog.
This is a very big deal. Here’s why:
It further simplifies and consolidates “boring” but very important data platform tech that has to be implemented in almost every company. The “Kafka to Data Lake” seems to be a solved problem with tools like Kafka Connect, but things quickly break at scale. A few years ago, I talked to the Head of Data Platform at a well-known gaming company, and he admitted that “Kafka to Data Lake” is still where the majority of their focus goes. They had 4000+ topics at the time with tricky schema evolution rules. This problem should become simpler, not harder, with time! I predicted more consolidation to happen here, so it’s nice to see some validation.
Tableflow also finally completes Kappa architecture. For a while now, Kappa architecture was criticized for the proposed backfill process (just read from the beginning of a topic, right?). It’s painfully slow, and the tiered storage is not an answer. So the ability to backfill fast (ideally in a batch fashion with some predicate pushdown if needed) and then switch to real-time is the most pragmatic way to implement it. Flink already supports Hybrid Source as a pattern. And if you think that this approach violates Kappa principles… I have bad news for you (from the famous Questioning the Lambda Architecture):

Also, one could argue that it’s possible to build a similar system with an Iceberg connector: just archive data to Iceberg and use it in the Hybrid Source. It’s very close indeed, but there is a significant difference - you’re dealing with derived data. It can be accurate and arrive with low latency, but it’s still outside of Kafka. But with Tableflow (or any similar implementation), you still read data from Kafka, just with a different interface.
I think Tableflow will take a lot of time to become mature. In my mind, this announcement is more of a statement: this is where we want to go. Redpanda announced their support for the Iceberg protocol 8 months ago; WarpStream also promised to support it. Now they’ll need to play catch up.

Talks
I managed to attend quite a few talks during the event! These were my favourites.
Evolve Your Schemas in a Better Way! A Deep Dive into Avro Schema Compatibility and Schema Registry
This was a very good refresher on schema compatibility rules. With great recommendations in the end.
Modifying Your SQL Streaming Queries on the Fly: The Impossible Trinity
Must watch! Modifying Streaming SQL queries is very hard indeed.
Yingjun has presented three dimensions for this: generality, efficiency, and consistency. In practice, you can choose only two.
He shared some simple rules that may allow a streaming engine to avoid recomputing its state. E.g., if you use a Top 10 computation and the user changes it to Top 5 you can actually reuse the state!
But in some situations, you can’t. It may affect data consistency. In this case, it’s recommended to just ask what the user wants.
Flink's SQL Engine: Let's Open the Engine Room!
Another amazing talk from Timo about Flink SQL internals.

He presented different execution layers and explained how different types of queries (append-only, upserts, with watermarks) are optimized and executed.
Tick, Tick, Tick….Time is Money When Processing Market Data
A great, practical example of different windowing strategies. I can recommend it if you have a hard time understanding the practicality of windowing and timers.
Semantic Validation: Enforcing Kafka Data Quality Through Schema-Driven Verification
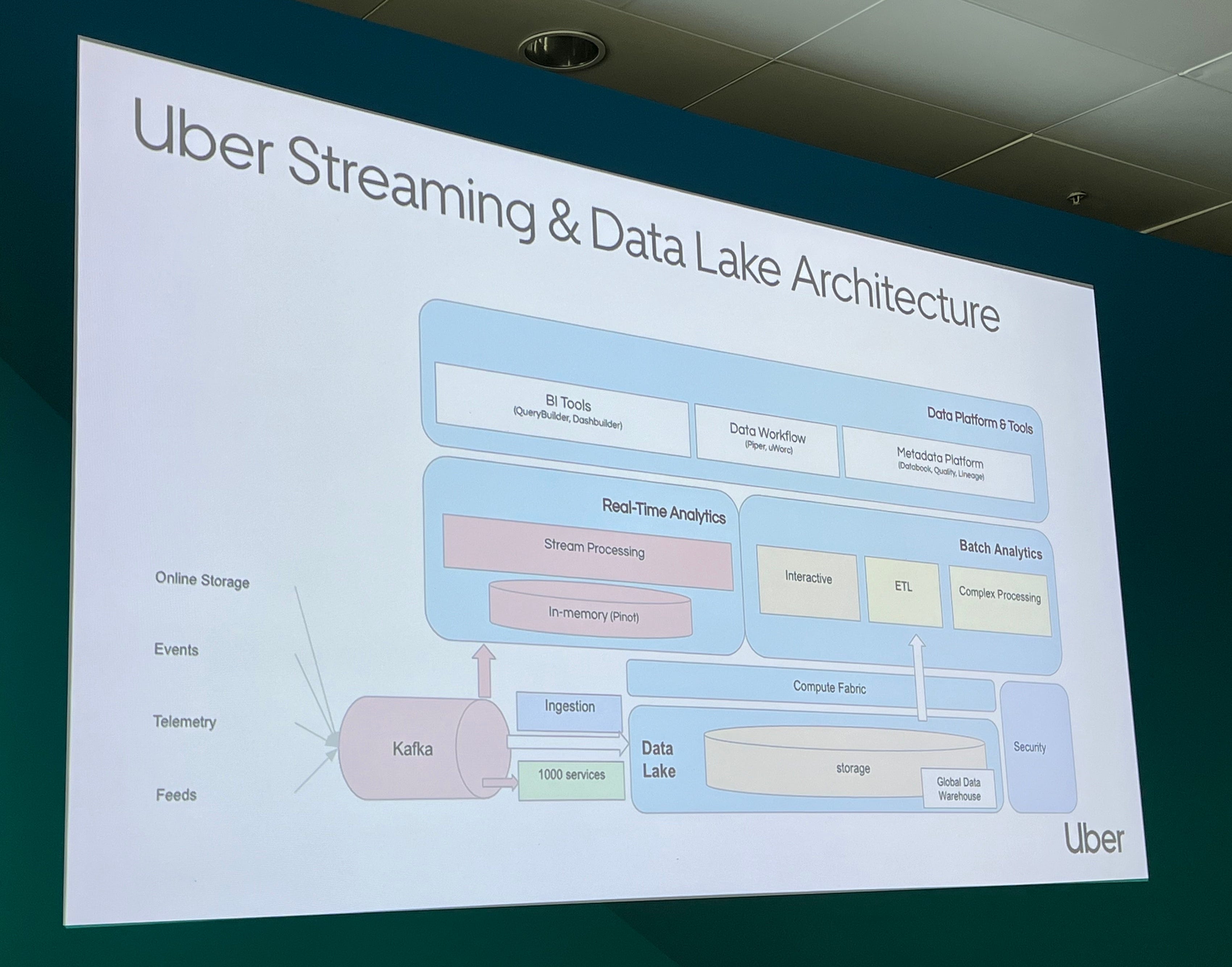
Xinli spent quite a bit of time explaining how Uber’s data platform works. No surprises here, but a great reference nonetheless.
Then Diwei explained the concept of semantic validation, which, in practice, turned out to be Avro schemas + business-level validation (e.g. “this int is actually age”). This feels like a flavour of data contracts.
Great talk overall, especially if you care about the quality of your data.
Flink 2.0: Navigating the Future of Unified Stream and Batch Processing
Solid Flink 2.0 overview from Martijn. He presented four key pillars:
Unification of batch and streaming.
SQL platform (update, delete statements; time travel).
Streaming Warehouses.
Engine Evolution (disaggregated storage, DataStream API v2).
He also promised that things would not break🤞.
Mastering Flink's Elasticity with the Adaptive Scheduler
Excellent talk on the Flink execution model and adaptive scheduling. Autoscaling is really hard when there are so many dimensions to measure. Highly recommend this to anyone running Flink in production.
Other Talks to Watch
I’ll definitely catch these ones:
Restate: Event-driven Asynchronous Services, Easy as Synchronous RPC.
OpenLineage for Stream Processing.
Exactly-Once Stream Processing at Scale in Uber.
AsyncAPI v3: What’s New?
Data Contracts In Practice With Debezium and Apache Flink.
Beyond Tiered Storage: Serverless Kafka with No Local Disks.
It's a Trap! Solving Restoration with Custom Kafka Streams State Stores.
Vendor of the Event
Datorios seemed the most interesting product to me. It’s an extremely powerful tool for analyzing Flink pipelines: it can visualize events, analyze windows and even view state! I can’t wait to try it.