
Streaming Platforms in the Cloud Era
An ode to WarpStream.

Please pledge your support if you find this newsletter useful. I’m not planning to introduce paid-only posts anytime soon, but I’d appreciate some support from the readers. Thank you!
WarpStream made a lot of noise with its announcement in July 2023. Kafka-compatible streaming platform based on object storage with no local disks! Some called it brilliant; some called it terrible. It made a huge impact nonetheless.
In July 2024, I’m confident to say that this is precisely where the industry is going. And instead of theorizing, I want to share my personal experience of running WarpStream in production at scale.
Recap
If you don’t breathe streaming platforms like some of us, let me summarize the architecture behind WarpStream. It’s quite simple and elegant:
Separate data in the data plane (e.g. payloads) from the metadata in the control plane (e.g. topic/partition information).
Use object storage as your primary (and only) data storage. Use compaction.
Make the data plane (“agents”) completely stateless.
Implement smart routing that can leverage cloud economics (e.g. traffic within the availability zone is free).
Finally, sprinkle everything with a bunch of intelligent optimizations like this one. As a result, you get a streaming platform with higher latency but superior in every other aspect.
Not Just WarpStream
Many people saw the clear benefits of a cloud-native architecture that WarpStream demonstrated. In the last 12 months:
Confluent has announced Freight Clusters.
StreamNative has announced Ursa for Apache Pulsar.
Perhaps it was too inspired by WarpStream…
AutoMQ, a cloud-native fork of Kafka, has made a similar announcement as well.
And a few new projects came out of stealth:
Tektite, not just a streaming platform but a stream-processing engine as well.
S2, tries to unify the ideas of object storage and data streaming even more.
Bufstream, provides tighter integration with the Schema Registry and Protocol Buffers.
It’s notable that some systems decided not to get rid of the disks completely. E.g., AutoMQ explained that low latency is still extremely important for the streaming workloads, so you should have an option of using EBS disk as a Write-Ahead-Log (more on this below).
I’m sure many other vendors are currently working on similar projects. But WarpStream was the first to use this architecture, so everyone will benefit from learning from its experience.
So here are some learnings.
Simplicity
I used to run and be on-call for Apache Kafka clusters. Large ones. In the cloud and on-prem.
I used Confluent Cloud and AWS MSK. I was a very early adopter of Redpanda Cloud.
I even used something called CloudKarafka (before the rename).
And after 7+ years of running and interacting with all these platforms, I can genuinely say that WarpStream is the easiest platform to run. No, I mean it. I even insisted on using the BYOC offering despite having a small team.
You just need to ensure that your WarpStream agents don’t go above 90% CPU. Ideally, with some autoscaling in place. That’s it. It’s nearly indestructible otherwise. You can casually 20x the traffic, observe the auto-scaling kick in, and the traffic spike is soaked!
You also don’t need to think about data skew and data rebalancing: everything is written to object storage and compacted right away.
The data/metadata separation and stateless agents make it that simple to run.
Software engineers outside of the data infra community have been criticizing Kafka for its complexity. But what if operating Kafka can be no different from operating a web service?
WarpStream talks a lot about the absence of inter-AZ traffic and the cost implications. In my opinion, the perceived simplicity of their architecture (on the user side) is more important.
Agent Roles
Even though WarpStream architecture looks simple, it’s flexible enough to support different types of topologies, something that's impossible with a regular set of Apache Kafka brokers.
For example, in addition to your regular agents, you can deploy an extra set of agents (an agent group) that only has the proxy-consume role, so you can have a dedicated read-only Kafka endpoint. Or the opposite, agents with the proxy-produce role could be used to only support data ingestion. Or you can offload compaction and other background jobs to dedicated set of agents with the jobs role.
This may eliminate the need to have different types of clusters optimized for different workloads, something I had to do a few years ago with Apache Kafka:
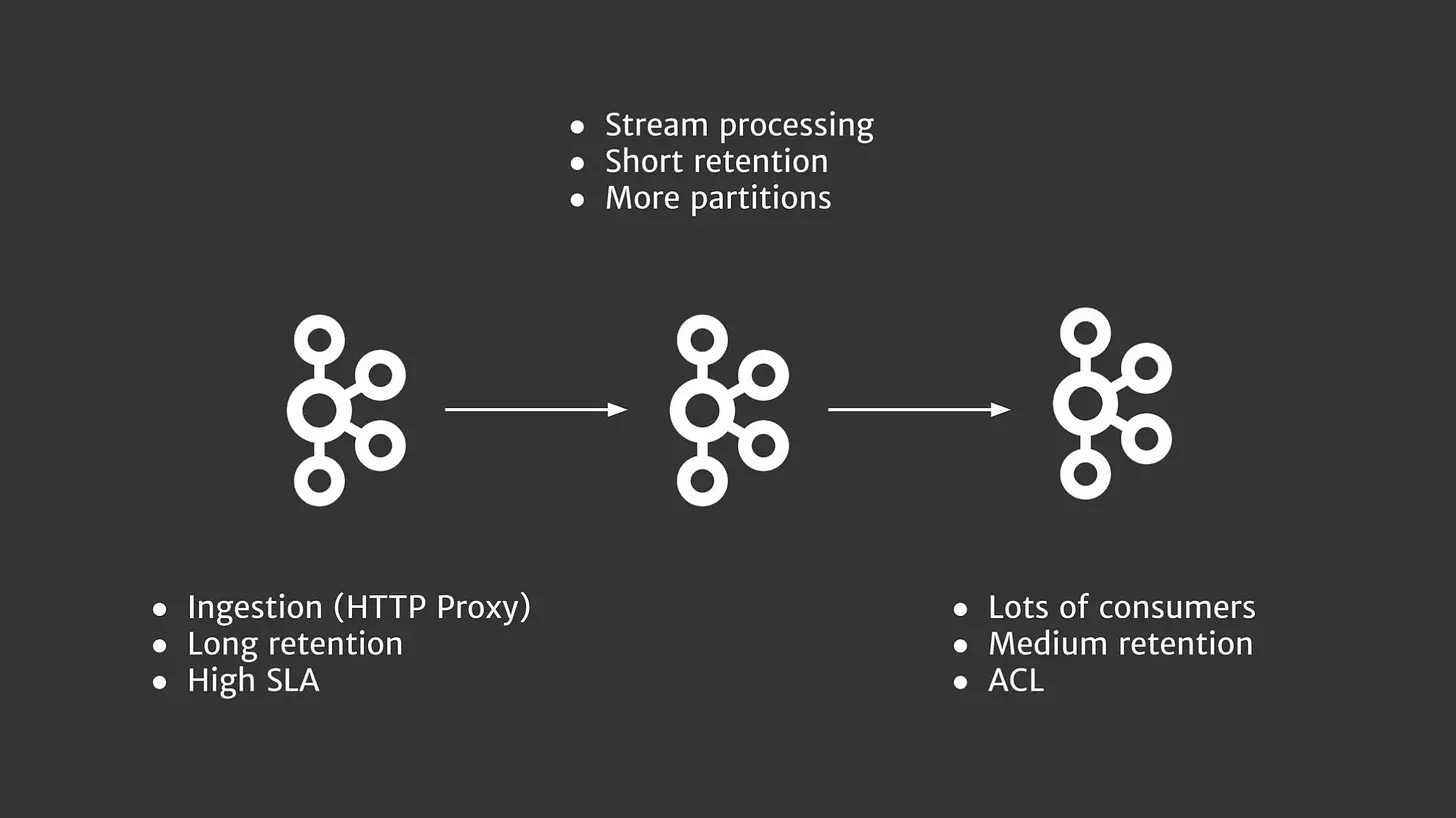
To clarify, this separation of roles is not really needed to implement WarpStream-like architecture. Other vendors may choose not to do it. But having it gives a lot of control to the users and can eliminate even more operational complexity.
Cost
Yes, it seems to be cheaper than alternatives.
Autoscaling helps a lot to avoid provisioning additional infrastructure to handle traffic spikes.
S3 is extremely cheap as a primary storage.
WarpStream doesn’t care how many partitions, active TCP connections or compacted topics you have (yep, all these are used by some vendors). The pricing model just tracks the throughput and the number of object storage requests.
And then there is the no inter-AZ traffic guarantee. This requires some setup on the client side, but it’s a one-time, straightforward config change. And here’s how you can achieve paying $0 for inter-AZ networking end-to-end:
Setup WarpStream BYOC and place at least one agent in each zone.
Ensure that each instance of a given stream-processing application (e.g. Apache Flink or Kafka Streams) is placed into the same AZ.
As a result, all traffic between your streaming platform (e.g. WarpStream) and stream-processing applications is constrained to a single AZ! Of course, this may not be what you want from the reliability perspective, but if you can tolerate some downtime while reassigning workloads between AZs, this can be a very attractive option. Of course, WarpStream is designed to fallback to other AZs in this scenario; you just need to ensure your stream-processing application is moved.
Despite the Azure announcement, I don’t believe AWS or GCP will stop charging for inter-AZ traffic soon.

“Free” Partitions
Well, not completely free, but close to that.
Due to the way WarpStream handles batching (any agent can batch data from any topic/partition together) AND the fact the metadata is separated, having an actively written partition incurs very low overhead. And having an inactive partition is almost free: you just need to store the metadata (and return it in the metadata requests).
This means that you can generally create more topics and don’t think too much about hitting a partition limit. You’ll be fine with tens of thousands of partitions with a few agents, as long as you don’t write to all of them at once. In my opinion, that’s why WarpStream doesn’t use partition count for billing or throttling.
This might seem like a small detail, but it brings WarpStream closer to the vision of the streaming-first data architecture I’ve been trying to popularize in the last few years. A streaming platform can be a better source of truth for your data infra. It needs a few things, and the ability to have more topics and more partitions without massive clusters is one of those (I mention another at the end).
What’s the Catch?
You need to configure and tune your clients certain way. This is a one-time investment, though.
Transactions are WIP (but you may be fine without them).
And then there is latency. By default, you get around a second of p99 end-to-end latency. You can easily shave off a few hundred milliseconds with a couple of simple config changes (like agent batching). It’s still going to be higher than what you get with Apache Kafka or Redpanda.
However, in my experience, this is perfectly fine for many data pipelines. Populating data lakes and/or data warehouses - totally fine. Change data capture for replicating data to search, cache or K/V database - fine. Ingesting observability data - probably fine. A lot of ML use cases like feature extraction are also fine.
Of course, there are some domains where you do need lower latency. Fraud detection, trading, online gaming, etc. Kafka-like platforms are also frequently used for messaging between microservices. And if you have several “hops” before triggering a user-facing action, for example, latency will add up quickly.
That’s why several vendors mentioned that you can’t just rely on object storage for low-latency use cases. AutoMQ, for example, mentions using EBS disks for low-latency Write-Ahead-Log.
In fact, I believe that WarpStream architecture already supports this use case. WarpStream can use the S3 Express One Zone bucket for landing data with low latency to one place and then use a compaction mechanism for moving data to the standard bucket for permanent storage. This brings p99 for the end-to-end latency to ~150ms. Even AutoMQ mentions S3 Express One Zone as an alternative to EBS.
I don’t think it’ll require much work (Richie, Ryan, forgive me for saying this 🙂) to generalize this approach, so a regular disk or a NoSQL database can be used instead for landing data. This can probably bring latency to tens of milliseconds, which makes it comparable to a typical streaming platform. Of course, it increases cost. And this is exactly how you need to balance this: cost vs latency.
Final Thoughts
WarpStream is not perfect. There are some rough edges, some APIs are not yet implemented. The Schema Registry support is still WIP.
But the fundamentals are solid. I’m so excited about the future and what WarpStream-like architecture allows us to do.
WarpStream really moves us closer to what I call streaming-first data architecture. The only missing piece right now is querying the data with something other than the Kafka protocol: REST API, Apache Iceberg integration, Trino connector or something similar. WarpStream already handles the storage, metadata and compaction needed for building the query engine.