
Can Kafka Queues Make Consumers Faster? Part 2: Head-Of-Line Blocking
Go slow to go fast.

A few weeks ago, I published my findings about the new Apache Kafka feature: Queues.

Check the post if you haven’t already!
I kept receiving the same feedback:
Obviously, with all the additional overhead that comes with Queues, it won’t be faster than a consumer with a much simpler standard consumer group (it wasn’t obvious to me 🤷).
Queues will likely perform much better when messages are processed with some delay, e.g., due to external IO. This is because Queues can essentially avoid hitting the Head-Of-Line Blocking problem.
Head-Of-Line Blocking?
Apache Kafka and similar systems use partitions as the smallest unit of parallelism. A topic with 4 partitions can be processed by up to 4 instances in the same consumer group (unless you add more groups reading the same topic, or start adding asynchronous message processing, which adds a lot of complexity very quickly).
And because only one instance processes a partition at a time, any delay in processing stalls the entire partition. For example, imagine a pipeline that needs to call an external API for enrichment for about half of the records. If that API is briefly unavailable, the pipeline can’t process any messages, even the ones that don’t need to be enriched.
Queues should solve this: a share group (new primitive) can have more active instances than partitions. My previous benchmark showed that this doesn’t really provide any advantage when message processing doesn’t have delays (so data is processed as fast as possible). So, let’s add some delays?
The Benchmark
The benchmark setup was identical to the one in the previous post.
The only difference: both standard and share group consumers had a configurable delay, modelling some kind of IO.
I wanted to see how delays affect throughput and whether share groups can keep scaling as new instances are added.
Results
I tried a few different delays:
200ms. Each instance could process records at a 5 rec/s rate.
20ms. Each instance could process records at a 50 rec/s rate.
5ms. Each instance could process records at a ~196 rec/s rate.
1ms. Each instance could process records at a ~925 rec/s rate.
The last two rates show that, at lower latencies, batch processing impact (Kafka consumer polls data in batches) becomes apparent.
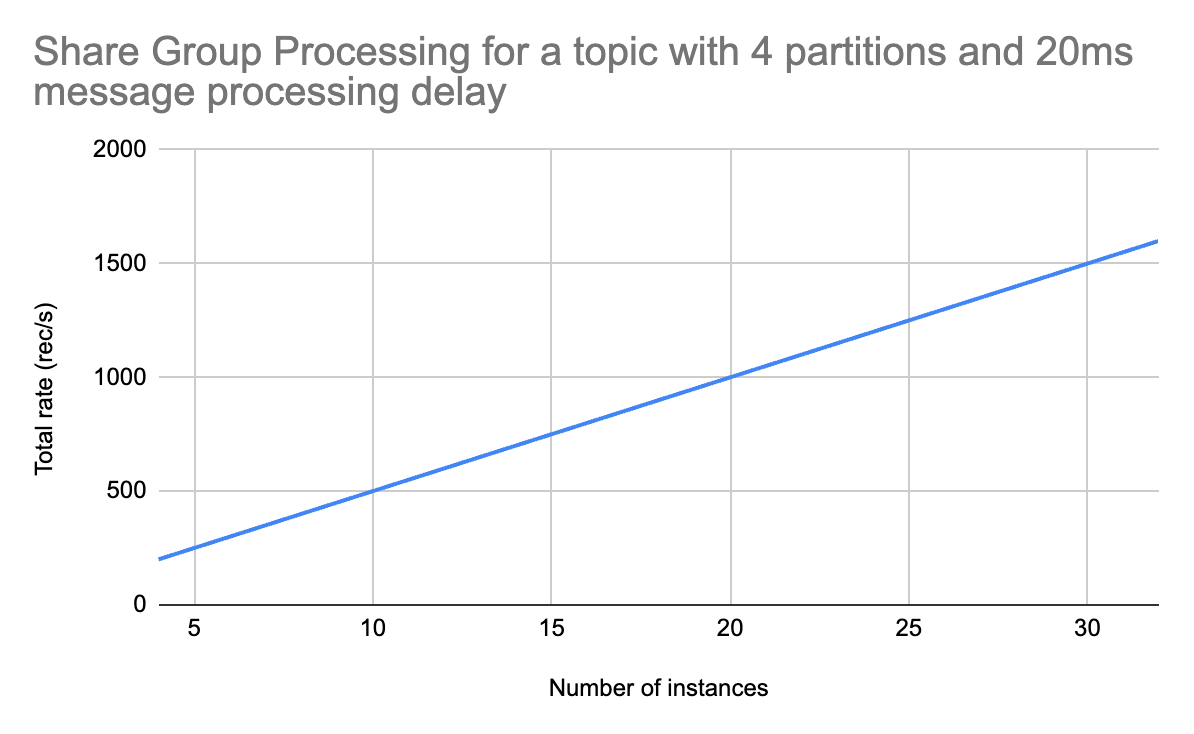
But what’s more important: the numbers looked exactly the same for the standard and the share consumer at 4 instances. I couldn’t scale out the standard consumer (the test topic only had 4 partitions). But the share consumer can be scaled out!
So I tried 8, 16 and 32 instances. And all of them showed a linear increase in the total processing rate! Individual instances performed at the same rate, and there was no overhead as the number of instances grew. This will likely hit a bottleneck at some point, but this test shows that it’s very easy to achieve at least an 8x increase in throughput!
Summary
Kafka Queues is a great building block for things like job queuing, but it can also be used for scaling consumers! As long as consumers perform some form of head-of-line blocking, share groups can be used to scale processing beyond the number of partitions.
The biggest downside is losing ordering guarantees. Because several instances can consume data from the same partition, the ordering is no longer guaranteed. This can be a deal-breaker for many systems, so make sure to confirm if ordering is important before switching to share groups!
Other Posts
I recently wrote Apache Flink: Postgres to Postgres Replication with Flink CDC, which you may find interesting.
Advanced Apache Flink
Advanced Apache Flink is an on-demand course focused on Flink internals, production deployment best practices, and advanced patterns.